

IMAGDressing-v1: Virtual Dressing Masa Depan – Perpindahan kebiasan belanja dari toko fisik seperti di pasar menjadi e-commerce online sudah terjadi beberapa dekade ini. Didorong oleh beberapa momentum dari mulai berkembang pesatnya startup hinga pandemi Covid-19.
Terdapat satu kata “Model” untuk makna yang berbeda, yaitu “Model” dalam peragaan pakaian dan “Model” dalam machine learning yang ditulis dengan huruf miring atau italic
Salah satu barang yang memiliki transaksi terbesar pada e-commerce adalah pakaian. Banyak platform belanja online berfokus pada penjualan pakaian, dikarenakan pakaian merupakan salah satu kebutuhan primer manusia.
Seringkali, penjual menghadapi kendala dalam menemukan model yang sesuai untuk mempresentasikan produk mereka, baik karena keterbatasan pilihan yang tersedia maupun karena keterbatasan anggaran untuk menyewa model profesional.
Hadirnya artificial Intelligence dapat menyelesaikan masalah tersebut. Implementasi dengan AI sebelumnya hanya dapat digunakan dengan pose yang sama dengan tampilan pakaian. Penggunaan diffusion model untuk meningkatkan pengalaman pengguna belanja online yang memungkinkan proses menampilkan pakaian oleh model menjadi lebih fleksibel.
Apa itu ImageDressing?
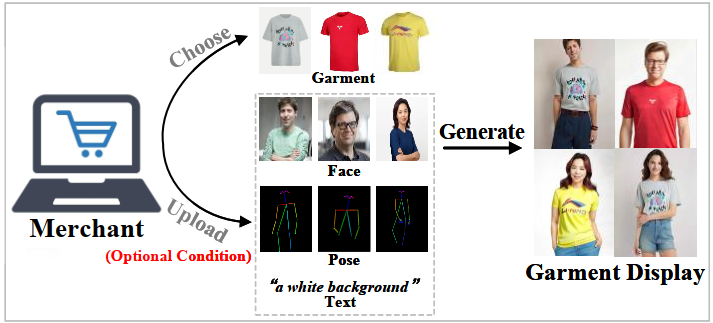
Diambil dari paper (Shen et al. 2024), IMAGDressing-v1 adalah model berbasis latent diffusion yang dirancang untuk tugas Virtual Dressing (VD). Virtual Dressing bertujuan untuk mencapai tampilan pakaian yang dapat dipersonalisasi oleh penjual atau pedagang dengan memanfaatkan pakaian yang diberikan serta opsi wajah, pose, dan teks.
Latent diffusion model adalah cara untuk membuat gambar berkualitas tinggi tanpa perlu komputasi berat. Bayangkan jika ingin menggambar lukisan detail, tetapi alih-alih langsung melukis di kanvas besar, yang dilakukan pertama adalah membuat sketsa kecil dulu, lalu memperbesarnya.
Metode VD dikembangkan dari virtual try-on (VTON), keduanya memiliki perbedaan:
- Sisi user experience:
- VTON membuat gambar berdasarkan pakaian dan model tertentu, sehingga hasilnya bersifat statis dengan hanya mengisi bagian yang diperlukan.
- VD lebih fleksibel karena berfokus pada pakaian dan memungkinkan pengguna menyesuaikan gambar dengan berbagai kondisi.
- Sisi penggunaan:
- VTON lebih cocok untuk konsumen yang ingin mencoba pakaian secara virtual sebelum membeli.
- VD lebih sering digunakan oleh penjual di e-commerce untuk menampilkan pakaian secara lebih fleksibel dan menarik.
- Sisi akurasi:
- VTON menitikberatkan pada transisi yang alami antara pakaian dan tubuh model.
- VD lebih fokus pada tampilan pakaian yang seragam dan estetis, sehingga cocok untuk menampilkan pakaian dalam berbagai skenario.
Dilatih dengan data yang berisi 300.000 pakaian dan pakaian yang digunakan. Model ini dapat menyelesaikan masalah utama pada Generative Adversial Network yang memiliki kelemahan pada min-max pada proses training.
Arsitektur
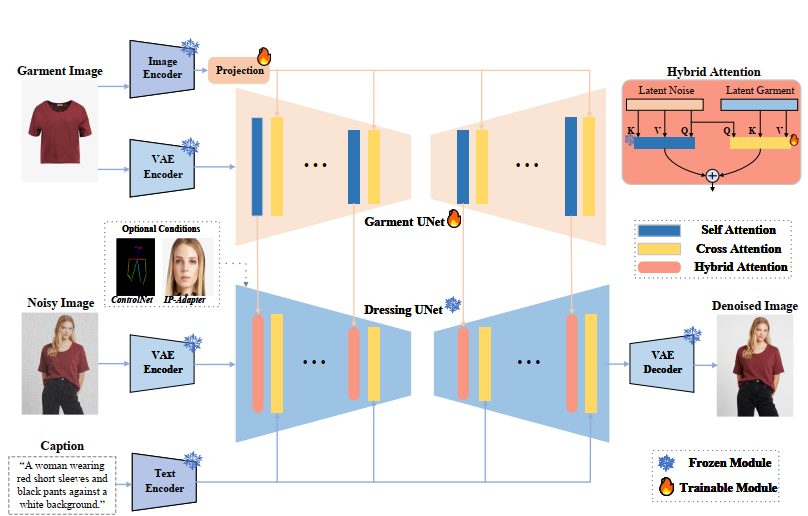
IMAGDressing-v1 terdiri dari dua komponen utama:
- Garment UNet: Mengekstrak fitur semantik melalui CLIP dengan menghubungkan antara gambar dan teks, serta mengekstrak tekstur melalui Variational autoencoder (VAE) dari gambar pakaian referensi.
- Denoising UNet (Dressing): Memproses latent noise untuk menghasilkan gambar akhir. Modul ini dilengkapi Hybrid Attention yang menggabungkan:
- Self-attention (frozen) untuk mempertahankan kemampuan generasi pemandangan dari teks.
- Cross-attention untuk menyisipkan fitur pakaian dari Garment UNet.
Implementasi

- Model: weight pada UNet untuk pakaian diinisialisasi dengan pre-trained weight dari UNet dalam Stable Diffusion v1.5 dan melakukan finetuning pada weight.
- Dataset: Tim peneliti merilis IGPair, dataset berisi 324.857 pasang gambar pakaian dan model manusia dengan resolusi 512 × 640
. Setiap gambar dilengkapi anotasi pose, segmen tubuh, dan deskripsi teks yang dihasilkan oleh model bahasa seperti BLIP2 dan LLaVA. - Pelatihan: Model dilatih menggunakan 10 GPU NVIDIA RTX3090 dengan batch size 5 selama 200.000 langkah. Optimizer AdamW dengan learning rate 5e-5 digunakan untuk memperbarui parameter Garment UNet dan modul cross-attention.
- Evaluasi: Metrik Comprehensive Affinity Metric Index (CAMI) mengukur konsistensi gambar hasil dengan pakaian referensi, mencakup struktur (CAMI-U) dan kesesuaian dengan kondisi tambahan seperti pose (CAMI-S).
Hasil
- Kuantitatif: IMAGDressing-v1 mengungguli metode SOTA seperti MagicClothing dan IP-Adapter pada semua metrik. Contohnya, nilai CAMI-U mencapai 1.753 (vs 1.655 pada MagicClothing) dan CAMI-S 2.719 (vs 2.692).
- Kualitatif:
- Hasil generasi tanpa kondisi spesifik (CAMI-U) mempertahankan detail seperti pola dan warna pakaian dengan lebih baik (Gambar diatas bagian a).
- Dengan kondisi spesifik (pose/wajah), IMAGDressing menghasilkan gambar yang lebih realistis dan sesuai permintaan teks (Gambar diatas bagian b).
- Fleksibilitas: Kombinasi dengan ControlNet-Inpaint memungkinkan aplikasi VTON dengan hasil high-fidelity
Kesimpulan
IMAGDressing-v1 merupakan terobosan dalam Virtual Dressing dengan kemampuan:
- Menghasilkan gambar manusia berpose alami dengan pakaian tetap dan kontrol terhadap teks/wajah/pose.
- Mempertahankan detail tekstur pakaian melalui arsitektur Hybrid Attention dan Garment UNet.
- Kompatibilitas tinggi dengan plugins seperti ControlNet dan IP-Adapter.
- Didukung dataset IGPair yang luas dan beranotasi lengkap.
Kontribusi ini membuka peluang aplikasi di e-commerce, hiburan, dan industri kreatif, di mana presentasi pakaian yang lebih dinamis dan menarik menjadi kunci keunggulan utama. Kode dan model telah tersedia secara terbuka untuk mendukung penelitian lebih lanjut.
Sumber:
- Shen, F., Jiang, X., He, X., Ye, H., Wang, C., Du, X., … & Tang, J. (2024). Imagdressing-v1: Customizable virtual dressing. arXiv preprint arXiv:2407.12705.
- Rombach, R., Blattmann, A., Lorenz, D., Esser, P., & Ommer, B. (2022). High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 10684-10695).
- Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., … & Sutskever, I. (2021, July). Learning transferable visual models from natural language supervision. In International conference on machine learning (pp. 8748-8763). PMLR.


