

Dall-e 2: Akankah Kecerdasan Buatan Menggantikan Seniman ? – Perkembangan kecerdasan buatan atau artificial intelligence (AI) yang cepat berdampak pada meluasnya bidang pekerjaan yang dapat dilakukan oleh AI, sehingga AI tidak hanya dapat melakukan pekerjaan yang berulang: membalas chat, membuat gambar realistik, dan memprediksi cuaca.
AI kini dapat membuat hal yang menakjubkan, yang berkaitan dengan imajinasi dan kreativitas manusia yaitu membuat lukisan atau gambar berdasarkan deskripsi singkat (caption) yang diberikan oleh pengguna.
Model pembuatan gambar berdasarkan deskripsi singkat diprakarsai oleh Elman Mansimov dkk. pada tahun 2015 dengan mengembangkan model Deep Recurrent Attention Writer (DRAW) yang diberi nama alignDRAW, sebuah model arsitektur machine learning untuk menghasilkan gambar berdasarkan dari keterangan yang diberikan. Model tersebut dilatih menggunakan dataset Microsoft COCO yang berisikan data 82.783 gambar dari berbagai kategori.

Salah satu model AI yang saat ini sedang populer adalah Dall-e yang dikembangkan oleh OpenAI. OpenAI adalah perusahaan yang bergerak dibidang penelitian dan pengimplementasian kecerdasan buatan. Dall-e populer berkat kemampuannya dalam menerjemahkan deskripsi singkat yang diberikan oleh manuasia menjadi gambar dalam berbagai macam style dari mulai lukisan kontemporer hingga foto hyperrealistic.
Sejarah Dall-e
Pada bulan Januari 2021 OpenAI merilis Dall·e versi 1. Dall-e versi pertama dikenal dengan Zero-Shot Text-to-Image Generation yang merupakan versi lain dari Generative Pre-trained Transformer versi 3 (GPT-3) dengan 12 miliar parameter.
Dall-e versi 1 dibuat dengan melakukan pelatihan terhadap Transformer (arsitektur encoder and decoder yang sudah dioptimasi untuk mengurangi sumber daya komputasi)untuk memodelkan gambar dan teks dalam satu aliran data.
Setahun setelah versi pertamanya rilis, pada tahun 2022 OpenAI merilis Dall-e 2 dengan peningkatan akurasi dan gambar yang dihasilkan jauh lebih realistik dengan ukuran resolusi gambar 4 kali lebih besar dari generasi sebelumnya. Tidak hanya menciptakan gambar, pada generasi keduanya Dall-e juga dilengkapi dengan fitur untuk meng-edit gambar dan membuat variasi dari gambar tersebut.
Berbeda dari versi pertamanya yang berbasiskan model GPT-3, di versi keduanya Dall-e menggunakan model Connecting Text and Images (CLIP) yang lebih efisien dalam mempelajari konsep visual.
Bagaimana Dall-e versi 2 Bekerja ?
Pada versi keduanya Dall·e menggunakan tahapan dua model: model pertama yang menghasilkan penyematan gambar (image embedding) pada CLIP dan diberi teks keterangan, dan model kedua adalah decoder yang menghasilkan gambar yang disesuaikan pada penyisipan gambar. Dengan dua tahapan ini dapat meningkatkan variasi gambar dan meminimalkan kehilangan hasil yang realistik pada gambar.
image embedding mengacu pada serangkaian teknik yang digunakan untuk mengurangi dimensi data gambar yang diproses pada neural network. image embedding bertujuan untuk mengurangi dimensi data untuk mempercepat proses pelatihan.
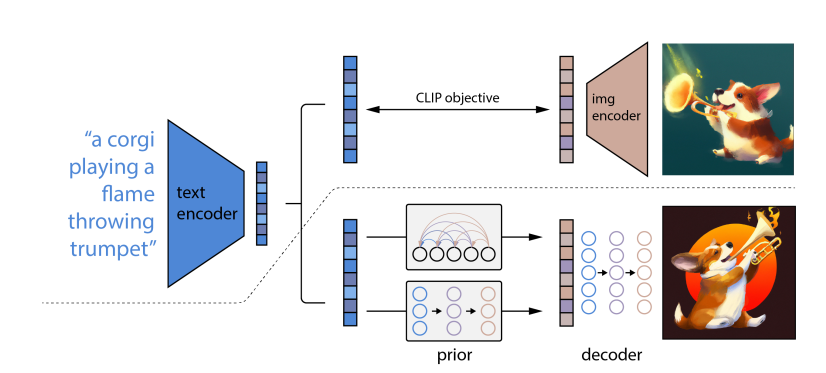
Pada bagian diatas gari putus-putus adalah proses pembelajaran CLIP, gambar dan teks sama-sama diambil datanya melalui proses encoding yang hasilnya kemudian dipelajari untuk mendapatkan kesamaan representasi antara teks dan gambar. Hasil dari gambar tersebut disematkan pada model CLIP sesuai dengan teks deskripsi singkat gambar tersebut.
Sedangkan pada bagian dibawah garis putus-putus adalah proses pembuatan text-to-image proses dari input teks sehingga menghasilkan output gambar atau pada model ini disebut dengan metode unCLIP. Pada prosesnya deskripsi teks melalui tahap encoding kemudian diproses dengan dua komponen prior dan decoder.
- prior bertugas membuat penyematan gambar pada CLIP berdasarkan dengan deskripsi singkat (caption) yang diberikan. prior menggunakan dua model kelas, yaitu: Autoregressive (AR) prior yang bertugas mengkonversi CLIP menjadi menjadi urutan kode diskrit dan diprediksi secara otomatis berdasarkan pada deskripsi dan Diffusion prior merupakan vektor berkesinambungan yang langsung dimodelkan menggunakan model difusi Gaussian yang didasarkan pada deskripsi singkat.
- decoder bertugas memproduksi gambar berdasarkan pada penyematan gambar CLIP. Pada decoder ini juga terjadi proses upscaling pada gambar untuk meningkatkan resolusi gambar menggunakan machine learning ditambah gaussian blur dan BSR degradation.
Cara membuat gambar dengan Dall-e
Cara membuat gambar yang dihasilkan oleh Dall-e cukup mudah, hanya perlu membuat akun di https://labs.openai.com/signup dan lakukan verifikasi. Selanjutnya anda akan mendapatkan credit sebesar 50 point yang dapat digunakan untuk mengintruksikan Dall-e membuat gambar atau lukisan sesuai deskripsi yang diberikan.

Kesimpulan
Kekhawatiran yang muncul oleh adanya ketakutan pekerjaan manusia digantikan oleh mesin adalah hal yang terjadi selama berabad-abad. Hal tersebut benar dan salah, karena selain beberapa pekerjaan yang saat ini sudah digantikan oleh teknologi mesin, tetapi juga ada pekerjaan yang baru karena teknologi tersebut yang belum ada sebelumnya, sebagai contoh digital marketing.
Hadirnya Dall-e membuka harapan akan potensi dari sejauuh mana kemampuan kecerdasan buatan di masa depan. Meskipun Dall-e masih memiliki keterbatasan untuk saat ini seperti kebergantungan pada data pada proses training dan kebenaran data itu sendiri, namun Dall-e menjadi satu langkah besar menuju penciptaan artificial general intelligence yang dapat menyaingi kecerdasan manusia.
Apakah menurut anda Dall-e dapat menggantikan peran seniman ?
Sumber:
- Mansimov, E., Parisotto, E., Ba, J. L., & Salakhutdinov, R. (2015). Generating images from captions with attention. arXiv preprint arXiv:1511.02793.
- Ramesh, A., Pavlov, M., Goh, G., Gray, S., Voss, C., Radford, A., … & Sutskever, I. (2021, July). Zero-shot text-to-image generation. In International Conference on Machine Learning (pp. 8821-8831). PMLR.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.
- Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., & Chen, M. (2022). Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125.
- Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., … & Sutskever, I. (2021, July). Learning transferable visual models from natural language supervision. In International Conference on Machine Learning (pp. 8748-8763). PMLR.


