

Jukebox: Membuat Musik dengan AI – Musik tak terpisahkan dari perkembangan peradaban manusia. Aransemen musik tertua di dunia “Hurrian Hymn No. 6,” diciptakan sekitar pada abad ke 14 sebelum masehi. Semakin berkembangnya zaman, variasi musik semakin lebih banyak dan aransemen juga menjadi lebih kompleks.
Perkembangan artificial intelligence (AI) dalam bidang audio tidak kalah cepat dibandingkan visual ataupun teks. Dalam bidang audio OpenAI merevolusi perkembangan kecerdasan buatan dengan menciptakan model yang dapat membuat musik dalam berbagai genre, termasuk klasik, pop, rock, dan jazz.
Sebelum Jukebox, ada beberapa model yang dapat membuat aransemen musik dengan instrumen yang spesifik:
- Piano
- Vocal
- Timbre
OpenAI merevolusinya dengan dapat menggabungkan beberapa instrumen musik dan mengharmonisasikannya menjadi satu kesatuan. Dengan cukup memberikan genre, artis, and lirik yang diinginkan, model ini dapat memberikan sample musik. Berikut adalah salah satu musik yang dibuat:
Arsitektur
Hierarchical VQ-VAE
Vector QuantisedVariational AutoEncoder (VQ-VAE) adalah model machine learning yang mempelajari representasi data diskrit. Dalam model VQ-VAE, data kontinu (sinyal audio) dikonversi menjadi representasi diskrit menggunakan kode dari codebook.
Data diskrit adalah data yang nilainya terbatas pada bilangan bulat dan hanya mencakup angka yang dapat dihitung sebagai bilangan bulat. Data diskrit memiliki jumlah yang terbatas, berbeda dengan data kontinu yang tidak terbatas.
Seperti namanya VQ-VAE terdiri dari dua metode:
Vector Quantisation (VQ)
- VQ adalah teknik yang digunakan untuk memetakan vektor input ke vektor diskrit yang berada dalam kumpulan vektor diskrit yang sudah ditentukan sebelumnya.
Variational AutoEncoder (VAE)
- VAE adalah model generatif yang digunakan untuk menghasilkan data baru dari distribusi data yang diberikan. VAE terdiri dari dua bagian utama: encoder dan decoder.
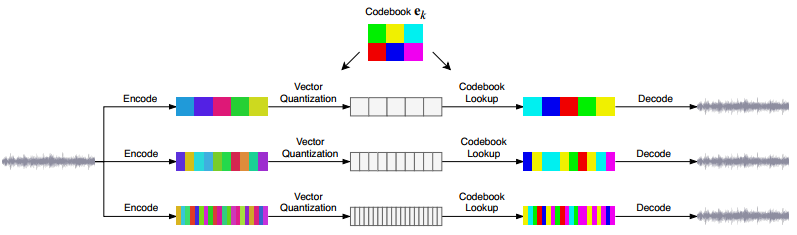
Dengan menggunakan teknik ini, model dapat menghasilkan representasi yang lebih efisien secara memori dan mengurangi kompleksitas model secara keseluruhan, sambil tetap mempertahankan kualitas dalam menghasilkan data baru.
Music VQ-VAE
OpenAI menyempurnakan VQ-VAE untuk pembuatan musik dengan menambahkan beberapa metode lainnya.
Random restarts for embeddings
VAE memiliki codebook yang berisi vektor-vektor. Dalam beberapa kasus, representasi diskrit dari codebook bisa menghasilkan kehilangan informasi yang signifikan dibandingkan dengan representasi kontinu.
Untuk menyelesaikan masalah tersebut, peneliti OpenAI menambahkan metode untuk mengatur ulang nilai secara acak. Dengan cara ini, semua vektor di codebook mendapatkan kesempatan untuk belajar dari data.
Separated Autoencoders
Selain dengan menggunakan metode random restart, penambahan metode autoencoders yang terpisah juga dilakukan untuk mencegah hilangnya informasi. Untuk memaksimalkan jumlah informasi yang disimpan di setiap level, pelatihan autoencoder dilakukan secara terpisah dengan panjang langkah yang bervariasi.
Spectral Loss
Metode spectral loss digunakan sebagai metrik evaluasi yang digunakan untuk membandingkan dua sinyal audio berdasarkan karakteristik spektral mereka. Jika ada dua sinyal audio yang dihasilkan oleh model Jukebox dan sinyal audio asli yang ingin dibandingkan, spectral loss membantu mengukur seberapa mirip kedua sinyal tersebut dalam hal spektrum frekuensi.
Tujuan dari menggunakan spectral loss adalah untuk membantu model Jukebox menghasilkan audio yang lebih berkualitas dan menyerupai sinyal asli sebanyak mungkin, terutama dalam hal kejernihan suara, inti frekuensi, dan penataan frekuensi.
Model Training
Dataset
Data untuk proses training Jukebox terdiri dari 1.2 juta lagu beserta lirik dan metadatanya (artis, album, genre, tanggal rilis, playlist keyword). Data yang ditaining mempunyai kualitas audio 32 bit, 44.1 kHz raw audio dengan beberapa audio melalui proses downmixing untuk memngubahnya dari channel stereo ke mono.
Training Process
Menggunakan 3 tingkat bottleneck yang memampatkan audio 44 kHz dalam dimensi sebesar 8x, 32x, dan 128x secara berturut-turut, dengan ukuran codebookl sebesar 2048 untuk setiap tingkat. VQ-VAE memiliki 2 juta parameter dan dilatih pada klip audio 9 detik pada 256 V100 selama 3 hari.
Upsampler menggunakan 8192 token kode VQ-VAE, yang setara dengan sekitar 24, 6, dan 1.5 detik raw audio di tingkat atas, tengah, dan bawah secara berturut-turut. Upsampler memiliki satu miliar parameter dan dilatih pada 128 V100 selama 2 minggu, dan tingkat atas memiliki 5 miliar parameter dan dilatih pada 512 V100 selama 4 minggu. Model dilatih dengan metode optimasi Adam dengan learning rate 0.00015 dan weight decay 0.002. Untuk lirik degan model pada 512 V100 selama 2 minggu.
Sumber:
- Dhariwal, P., Jun, H., Payne, C., Kim, J. W., Radford, A., & Sutskever, I. (2020). Jukebox: A generative model for music. arXiv preprint arXiv:2005.00341.
- Van Den Oord, A., & Vinyals, O. (2017). Neural discrete representation learning. Advances in neural information processing systems, 30.
- Van Den Oord, A., Dieleman, S., Zen, H., Simonyan, K., Vinyals, O., Graves, A., … & Kavukcuoglu, K. (2016). Wavenet: A generative model for raw audio. arXiv preprint arXiv:1609.03499, 12.
- Kingma, D. P., & Ba, J. (2014). Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
