

Whisper: AI yang Mampu Mengenali Suara Manusia – Apakah anda familiar dengan kalimat perkataan’hey siri’ atau ‘ok google’ ? kedua kalimat tersebut diucapkan untuk mengaktifkan asisten virtual Apple dan Google. Setelah kata tersebut diucapkan biasanya dilanjutkan dengan perkataan perintah dari pengguna untuk mengintruksikan asisten virtual untuk mencari informasi atau melakukan sesuatu. Pernahkah terbersit dalam pikiran anda tentang bagaimana Apple Siri dan Google dapat mengenali perkataan anda ?
Whisper, model yang dikembangkan oleh OpenAI yang memiliki fungsi untuk membuat transkrip dari audio, memiliki kemampuan multibahasa dan dilatih dengan data dari 680.000 jam audio atau setara dengan sekitar 78 tahun durasi audio.
Data
Data audio beserta transkrip untuk pelatihan model diambil dari internet dan yang digunakan sangat bervariasi baik dari segi sumber suara dan bahasanya. Karena sebagian besar data yang ada pada internet tidak dibuat langsung oleh manusia, melainkan oleh sistem Automatic Speech Recognition (ASR) yang otomatis membuat suara berdasarkan audio, oleh karena itu maka pembersihan terhadap data dilakukan dengan menghapus transkrip yang dibuat dari ASR.
Proses selanjutnya adalah mengecek bahasa dari data audio, untuk memudahkan pengkategorian bahasa, peneliti menggunakan pendeteksi bahasa dari model yang telah di fine-tuning dari prototipe model yang telah dilatih menggunakan dataset VoxLingua107. Jika ditemukan bahasa dan transkrip yang sesuai maka data tersebut dihapus dari dataset.
Arsitektur Whisper
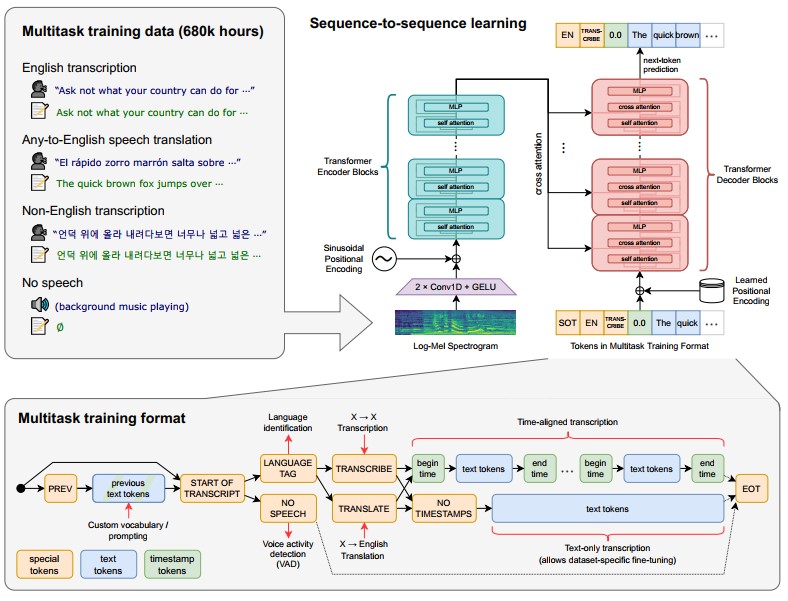
Sequence-to-sequence Learning
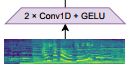
Audio input diubah menjadi spektrogram log-Mel yang memvisualisasikan spektrum frekuensi audio. Arsitektur Whisper dibangun dengan dari encode-decoder Transformer. Pada encoder terdiri dari dua convolutional layer lebar filter 3 dan Gaussian Error Linear Unit (GELU) sebagai activation function. Pada convolutional layer kedua memiliki langkah konvolusi (stride) dua.
Proses ini dapat disebut sebagai stem yang mana adalah bagian awal dari arsitektur model yang bertugas memproses input mentah dan mengubahnya menjadi representasi yang lebih cocok untuk tahap pemrosesan berikutnya dalam model.
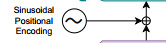
Sinusoidal position embeddings kemudian ditambahkan ke output dari stem, setelah itu blok-blok Transformer encoder diterapkan. Fungsi ini berguna untuk memahami dan memproses urutan elemen dalam data secara efektif.
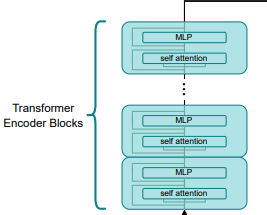
Encoder bertugas untuk memproses input audio dan menghasilkan representasi yang mendalam. Transformer menggunakan blok residual pra-aktivasi dan normalisasi diterapkan pada lapisan akhir output.

Decoder bertugas untuk menghasilkan transkripsi teks berdasarkan representasi dari encoder. Encoder dan decoder memiliki lebar dan jumlah blok transformer yang sama. Untuk yang berbahasa Inggris, Whisper menggunakan tokenizer yang sama dengan yang digunakan pada GPT-2.
Multitask Training Format
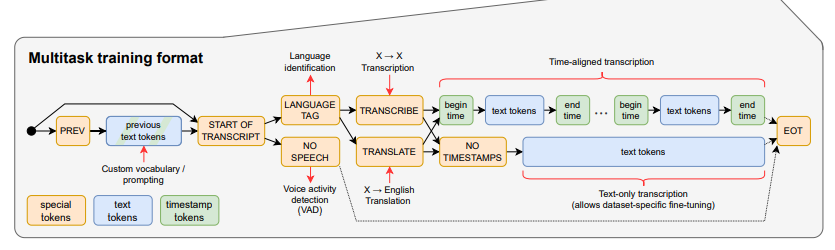
Multitask Training Format pada arsitektur Whisper AI adalah pendekatan untuk pelatihan model di mana model dilatih untuk melakukan berbagai tugas pemrosesan token secara bersamaan.
Pada proses ini token dibagi menjadi tiga bagian:
- Special Tokens: Token khusus untuk menentukan jenis tugas dan metadata lainnya.
- Text Tokens: Token yang dihasilkan atau diproses.
- Timestamp Tokens: Token penanda waktu yang digunakan untuk transkripsi untuk menyesuaikan dengan waktu dalam audio.
Pada setiap token diberikan tag terkait tugas masing-masing:
- Language Tag: Tag untuk identifikasi bahasa dari data input.
- Transcribe/Translate: Melakukan transkripsi atau menerjemahkan.
- Voice Activity Detection (VAD): Digunakan untuk mendeteksi ucapan dalam audio input.
Sedangkan berdasarkan letak atau waktu inputnya:
- Start of transcript: Token awal yang menandai dimulainya transkripsi.
- Transcrine/Translate: Menentukan apakah tugas adalah transkripsi atau terjemahan.
- Begin/End Time Tokens: Token yang menandai waktu mulai dan berakhirnya ucapan dalam transkripsi.
- EOT (End Of Transcript): Token yang menandai akhir dari transkripsi.
Sumber:
- Radford, A., Kim, J. W., Xu, T., Brockman, G., McLeavey, C., & Sutskever, I. (2023, July). Robust speech recognition via large-scale weak supervision. In International Conference on Machine Learning (pp. 28492-28518). PMLR.
- Benzeghiba, M., De Mori, R., Deroo, O., Dupont, S., Erbes, T., Jouvet, D., … & Wellekens, C. (2007). Automatic speech recognition and speech variability: A review. Speech communication, 49(10-11), 763-786.
- Child, R., Gray, S., Radford, A., & Sutskever, I. (2019). Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509.
