

Saat ini, kecerdasan buatan (AI) sudah bisa menjawab banyak pertanyaan. Namun, AI sering kesulitan jika diberi tugas riset yang rumit, jenis tugas yang mengharuskan kita membuka banyak situs, membandingkan data, dan menarik kesimpulan. Masalahnya, AI belum dilatih dengan cara yang tepat untuk melakukan penalaran beberapa langkah seperti itu.
Untuk mengatasi tantangan ini, para peneliti di Tongyi Lab, Alibaba Group, menciptakan WebDancer. Ini adalah sebuah metode lengkap untuk membangun dan melatih AI agar bisa berpikir dan bertindak layaknya seorang peneliti manusia saat menjelajahi internet.
WebDancer, sebuah model untuk membangun agen pencari informasi yang otonom secara end-to-end. WebDancer menyajikan sebuah kerangka kerja sistematis yang berfokus pada data dan tahapan pelatihan untuk menghasilkan agen web yang mampu melakukan tugas-tugas riset yang rumit.
Arsitektur
Kerangka kerja WebDancer dibangun di atas empat tahap utama yang dirancang untuk secara progresif membangun kemampuan agen.
- Konstruksi Data Penelusuran: Tahap pertama adalah membuat kumpulan data pertanyaan dan jawaban (QA) yang beragam dan kompleks. Kumpulan data ini sengaja dirancang untuk memancing penalaran model dan memerlukan beberapa interaksi dengan lingkungan web untuk dapat diselesaikan.
- Pengambilan Sampel Trajektori: Setelah QA dibuat, tahap selanjutnya adalah menghasilkan “trajektori” atau solusi berkualitas tinggi. Trajektori ini adalah serangkaian langkah pemikiran dan tindakan yang menunjukkan cara menyelesaikan sebuah pertanyaan. Proses ini menggunakan model bahasa (LLM) yang kuat untuk menghasilkan urutan Thought-Action-Observation sesuai dengan kerangka kerja ReAct, yang kemudian disaring secara ketat untuk memastikan kualitasnya.
- Supervised Fine-Tuning (SFT): Pada tahap ini, model agen dilatih menggunakan trajektori berkualitas tinggi yang telah dikumpulkan. SFT berfungsi sebagai “cold start” yang efektif, mengajarkan model untuk mengikuti format instruksi dan perilaku dasar agen, seperti bagaimana menyusun pemikiran dan memanggil tools yang sesuai.
- Reinforcement Learning (RL): Tahap terakhir adalah mengoptimalkan kemampuan pengambilan keputusan dan generalisasi agen melalui Reinforcement Learning. Dengan menggunakan umpan balik berbasis hasil (reward), agen belajar untuk menyempurnakan perilakunya dalam berinteraksi dengan lingkungan web yang dinamis, sehingga meningkatkan pemahamannya dalam menghadapi skenario yang tidak terduga.
Data
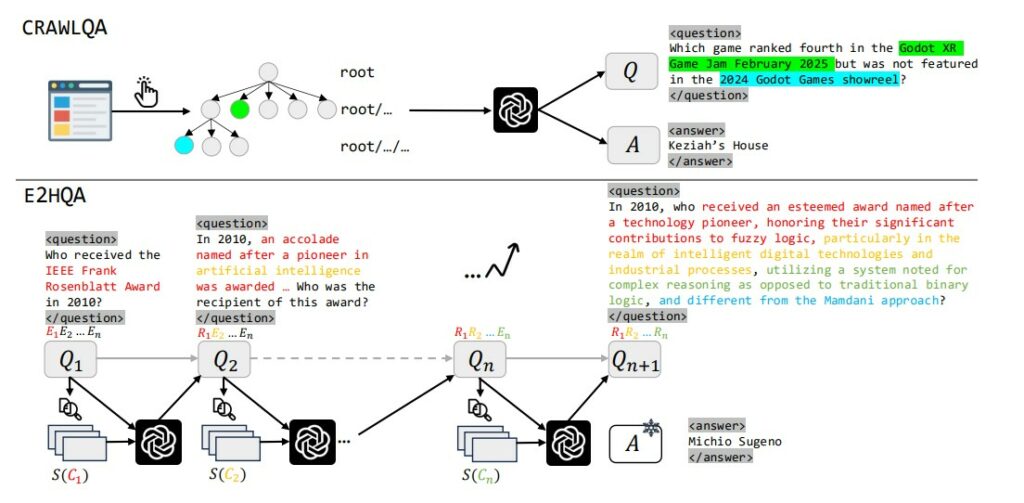
Kualitas data pelatihan adalah faktor krusial dalam membangun agen web yang kompeten. WebDancer menggunakan dua metode sintesis data untuk menghasilkan QA yang terbaik:
- CRAWLQA: Metode ini secara otomatis membuat QA dengan melakukan crawling pada situs web yang kaya akan pengetahuan, seperti arxiv, github, dan wiki. Sistem ini menavigasi halaman dan sub-halaman, lalu menggunakan model LLM (GPT-4o) untuk menghasilkan pertanyaan-pertanyaan yang jawabannya tersembunyi di dalam konten yang dikumpulkan.
- E2HQA (Easy-to-Hard QA): Teknik ini dimulai dengan pertanyaan sederhana, lalu secara iteratif membuatnya menjadi lebih kompleks. Proses ini dilakukan dengan mengganti sebuah entitas dalam pertanyaan dengan deskripsi atau petunjuk. Akibatnya, untuk menjawab pertanyaan utama, agen harus terlebih dahulu menyelesaikan sub-masalah untuk mengidentifikasi entitas tersebut, sehingga meningkatkan jumlah langkah penalaran yang diperlukan.
Proses Pelatihan
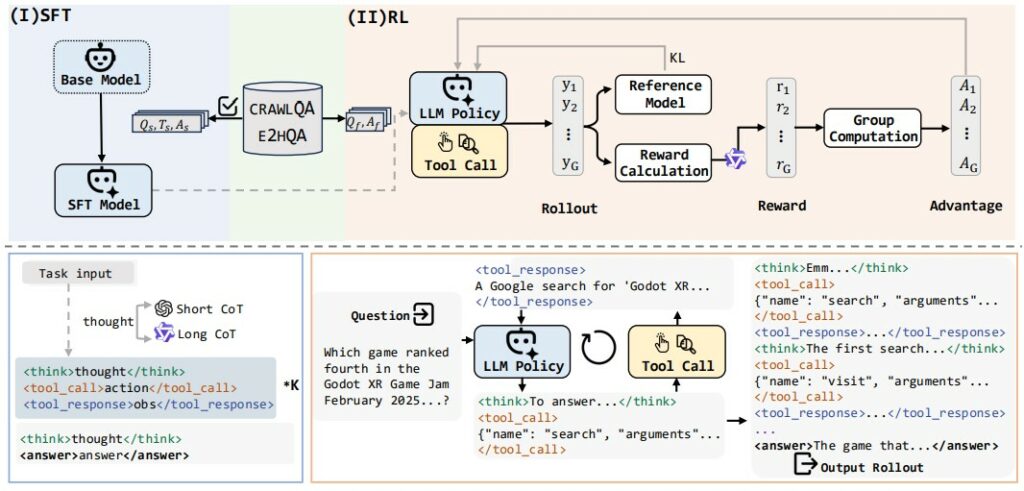
WebDancer menerapkan pipeline pelatihan dua tahap untuk menanamkan kemampuan agen secara efektif.
- Fase 1: Supervised Fine-Tuning (SFT): Model agen dilatih pada trajektori yang telah diformat dalam gaya ReAct. Tujuan utama dari SFT adalah agar model menginternalisasi paradigma perilaku agen yang menghubungkan antara penalaran dan tindakan. Selama pelatihan, kontribusi loss dari token observasi diabaikan untuk membuat model fokus belajar pada proses pengambilan keputusannya sendiri.
- Fase 2: Reinforcement Learning (RL): Setelah SFT memberikan fondasi yang kuat, model disempurnakan lebih lanjut menggunakan RL. Kerangka kerja ini mengimplementasikan algoritma Decoupled Clip and Dynamic Sampling Policy Optimization (DAPO). Selama fase RL, agen secara aktif berinteraksi dengan lingkungan untuk menyelesaikan tugas. Kebijakannya diperbarui berdasarkan fungsi reward yang mempertimbangkan kebenaran jawaban akhir dan validitas format tool call.
Implementasi
Hasil eksperimen menunjukkan bahwa pendekatan WebDancer memberikan peningkatan kinerja yang substansial dibandingkan dengan implementasi ReAct standar (vanilla ReAct) pada berbagai skala model. Sistem yang tidak memiliki kemampuan agen menunjukkan performa yang sangat buruk, yang menggarisbawahi perlunya pencarian informasi aktif untuk tugas-tugas ini. Yang terpenting, WebDancer yang dibangun di atas model QwQ-32B menunjukkan kinerja yang sangat kuat, bahkan melampaui GPT-4o.
Kesimpulan
Paper ini memperkenalkan WebDancer, sebuah kerangka kerja yang sistematis dan end-to-end untuk membangun agen web pencari informasi. Kontribusi utamanya terletak pada metode sintesis data QA yang skalabel (CRAWLQA dan E2HQA) dan pipeline pelatihan dua tahap yang menggabungkan SFT untuk fondasi awal dengan RL untuk optimalisasi dan generalisasi.
Implikasi dari penelitian ini adalah tersedianya jalur yang sistematis dan dapat ditindaklanjuti bagi komunitas untuk mengembangkan model agen yang lebih canggih dan mampu menangani tugas-tugas pencarian informasi yang kompleks di dunia nyata. Meskipun demikian, penelitian ini memiliki beberapa batasan, termasuk jumlah dan jenis alat yang masih terbatas, fokus pada tugas dengan jawaban singkat, serta biaya komputasi yang tinggi pada fase RL.
Sumber:
- Wu, J., Li, B., Fang, R., Yin, W., Zhang, L., Tao, Z., … & Zhou, J. (2025). WebDancer: Towards Autonomous Information Seeking Agency. arXiv preprint arXiv:2505.22648.
- Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2023). ReAct: Synergizing reasoning and acting in language models. In International Conference on Learning Representations (ICLR).
