

Pembelajaran Berbasis Memori AI – Agen Large Language Model (LLM) yang ada saat ini menghadapi dua batasan fundamental. Pertama adalah mengandalkan kerangka kerja khusus dengan alur kerja yang kaku dan penalaran yang di-hardcode, sehingga kurang fleksibel dan tidak dapat beradaptasi dengan situasi baru setelah diimplementasikan.
Kedua, terlalu berfokus pada parameter LLM melalui fine-tuning atau reinforcement learning, yang memungkinkan perilaku yang lebih fleksibel tetapi membutuhkan biaya komputasi yang sangat tinggi dan tidak efisien untuk adaptasi berkelanjutan.
Hal ini menimbulkan tantangan riset utama yaitu bagaimana membangun agen LLM yang dapat belajar secara terus-menerus dari lingkungan yang berubah tanpa biaya mahal untuk melakukan fine-tuning pada model LLM dasarnya?
Paper ini memperkenalkan Memento, sebuah paradigma pembelajaran berbasis memori yang memungkinkan adaptasi berkelanjutan tanpa memodifikasi parameter LLM. Solusi ini menggunakan memori eksternal untuk menyimpan memori masa lalu, termasuk keberhasilan dan kegagalan untuk memandu pengambilan keputusan di masa depan, sejalan dengan prinsip-prinsip Case-Based Reasoning (CBR).
Arsitektur
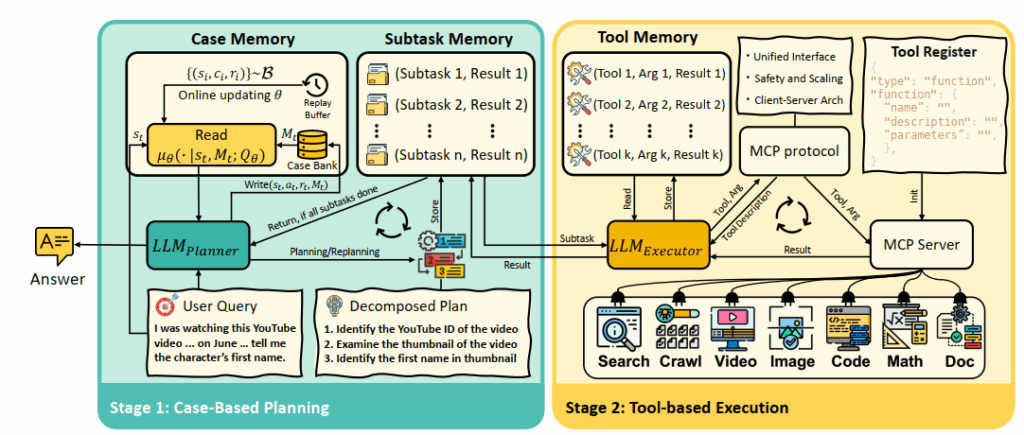
Memento diimplementasikan sebagai arsitektur planner-executor yang beroperasi dalam sebuah siklus berulang.
- Planner: Merupakan agen CBR yang digerakkan oleh LLM. Ketika menerima instruksi tugas, Planner akan mengirim kueri ke Case Memory untuk mengambil kasus-kasus relevan dari masa lalu. Kasus-kasus yang diambil ini berisi tugas, rencana, dan indikator keberhasilan digunakan untuk memandu LLM dalam menghasilkan rencana baru yang terbagi menjadi serangkaian sub-tugas.
- Executor: Merupakan klien berbasis LLM yang bertanggung jawab untuk mengeksekusi setiap sub-tugas yang diberikan oleh Planner. Executor dapat memanggil serangkaian tools eksternal (seperti pencarian web, eksekusi kode, pemrosesan dokumen) melalui sebuah antarmuka terstandardisasi yang disebut Model Context Protocol (MCP).
- Memory Modules: Arsitektur ini mengintegrasikan tiga modul memori: Case Memory: Penyimpanan berbasis vektor untuk kasus-kasus sebelumnya yang digunakan untuk perencanaan tingkat tinggi; Subtask Memory: Penyimpanan berbasis teks untuk sub-tugas yang aktif dan hasilnya, yang berfungsi untuk mengatur interaksi antara Planner dan Executor; Tool Memory: Catatan berbasis teks dari interaksi alat untuk setiap sub-tugas.
Data
Model Memento tidak dilatih secara konvensional, melainkan dievaluasi pada empat benchmark untuk menguji kemampuannya dalam berbagai skenario. Pengalaman yang diperoleh dari penyelesaian tugas-tugas di-benchmark inilah yang digunakan untuk mengisi Case Memory. Dataset yang digunakan adalah:
- GAIA: Terdiri dari pertanyaan-pertanyaan yang memerlukan penggunaan alat jangka panjang dan perencanaan otomatis, dengan tiga tingkat kesulitan.
- DeepResearcher: Kumpulan dari tujuh dataset Question Answering (QA) domain yang terbuka untuk menguji riset web secara real-time.
- SimpleQA: Terdiri dari 4.330 pertanyaan pencarian fakta untuk menguji akurasi faktual.
- HLE (Humanity’s Last Exam): Terdiri dari 2.500 pertanyaan di berbagai subjek akademis untuk menilai batas penalaran domain luas.
Training
Proses pembelajaran pada Memento tidak melibatkan fine-tuning atau pembaruan gradien pada parameter LLM dasar, menggunakann model LLM frozen. Pembelajaran terjadi di dalam mekanisme memori melalui dua pendekatan Case-Based Reasoning (CBR):
- Non-Parametric CBR: Dalam metode ini, operasi tulis (Write) hanya menambahkan kasus historis (status, tindakan, imbalan) ke dalam data bank kasus. Operasi baca (Read) kemudian mengambil kasus berdasarkan kesamaan semantik antara status tugas saat ini dan status-status yang tersimpan di memori.
- Parametric CBR: Metode ini lebih dinamis. Saat operasi tulis, selain menyimpan kasus baru, sistem juga memperbarui sebuah fungsi-Q secara online. Fungsi-Q ini dilatih untuk memprediksi utilitas dari setiap kasus yang tersimpan untuk tugas saat ini. Operasi baca kemudian menggunakan fungsi-Q yang telah dipelajari ini untuk melakukan pemilihan kasus secara adaptif. Proses pembaruan fungsi-Q disederhanakan menjadi objektif single-step Q-learning.
Implementasi
Memento menunjukkan kinerja yang sangat kuat di semua benchmark yang diuji, sering kali mengungguli sistem state-of-the-art lainnya.
- Pada GAIA, Memento mencapai peringkat 1 pada set validasi dengan akurasi 87.88% (Pass@3) dan mencapai 79.40% pada set pengujian.
- Pada DeepResearcher, Memento mencapai skor F1 66.6% dan PM 80.4%, melampaui sistem berbasis pelatihan yang ada.
- Pada SimpleQA, Memento mencapai akurasi 95.0%, mengungguli baseline agen web lainnya seperti WebSailor (93.5%) dan WebDancer (90.5%).
- Pada HLE, Memento mencapai skor 24.4% PM, menempati peringkat kedua secara keseluruhan, hanya 0.92 poin di bawah GPT-5 dan di atas Gemini-2.5 Pro (21.64%).
Studi ablasi menunjukkan bahwa komponen CBR secara konsisten memberikan peningkatan kinerja yang aditif. Penambahan memori berbasis kasus meningkatkan akurasi absolut sebesar 4.7% hingga 9.6% pada tugas-tugas out-of-distribution.
Kesimpulan
Memento adalah sebuah paradigma pembelajaran berbasis memori yang memungkinkan agen LLM untuk beradaptasi secara online tanpa memperbarui bobot model. Kerangka kerja ini memformalkan agen sebagai Memory-based Markov Decision Process (M-MDP) dan mengimplementasikannya dalam arsitektur planner-executor yang memanfaatkan bank kasus episodik.
Pendekatan ini menawarkan jalur yang skalabel dan efisien untuk pengembangan agen LLM generalis yang mampu belajar secara terus-menerus dan real-time tanpa pembaruan gradien.
Studi menunjukkan bahwa kurasi memori sangat penting, karena hasil optimal dicapai dengan mengambil sejumlah kecil kasus berkualitas tinggi. Pekerjaan di masa depan dapat berfokus pada pengembangan lebih lanjut tugas-tugas riset mendalam menggunakan kerangka kerja M-MDP berbasis memori ini.
Sumber:
- Zhou, H., Chen, Y., Guo, S., Yan, X., Lee, K. H., Wang, Z., … & Wang, J. (2025). Memento: Fine-tuning llm agents without fine-tuning llms. Preprint.
- Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2023, January). React: Synergizing reasoning and acting in language models. In International Conference on Learning Representations (ICLR).
- Schick, T., Dwivedi-Yu, J., Dessì, R., Raileanu, R., Lomeli, M., Hambro, E., … & Scialom, T. (2023). Toolformer: Language models can teach themselves to use tools. Advances in Neural Information Processing Systems, 36, 68539-68551.
- Guo, S., Deng, C., Wen, Y., Chen, H., Chang, Y., & Wang, J. (2024). Ds-agent: Automated data science by empowering large language models with case-based reasoning. arXiv preprint arXiv:2402.17453.
