

Light-A-Video adalah teknik terbaru yang memungkinkan mengubah pencahayaan dalam video tanpa memerlukan model khusus. Dikembangkan oleh tim peneliti dari Shanghai Jiao Tong University dan beberapa institusi lainnya. Tantangan utama dalam video relighting adalah menjaga konsistensi temporal. Artinya, pencahayaan, bayangan, dan pantulan harus terlihat alami dan bergerak secara mulus dari satu frame ke frame berikutnya.
Light-A-Video mengatasi masalah tersebut dengan menggabungkan kekuatan dua jenis model yang sudah ada:
- Model Image Relighting: Seperti IC-Light, yang sangat baik dalam mengubah pencahayaan pada satu gambar.
- Model Video Diffusion: Seperti AnimateDiff, yang memiliki pemahaman bawaan tentang bagaimana gerakan dan penampilan objek harus konsisten dari waktu ke waktu dalam sebuah video.
Arsitektur
Proses dimulai dengan video asli yang diberi noise (gangguan acak), lalu sebuah model video diffusion bertugas untuk menghilangkan noise tersebut secara bertahap dalam beberapa langkah untuk merekonstruksi video. Light-A-Video memiliki dua komponen utama yang bekerja bersama untuk menghasilkan video dengan pencahayaan yang konsisten dan natural:
Consistent Light Attention (CLA)
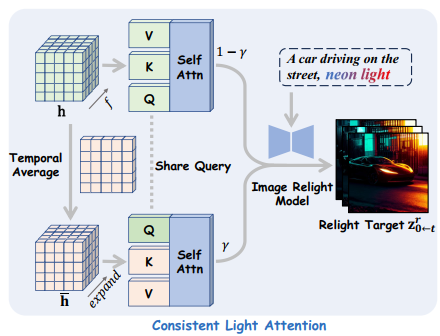
Pada setiap langkah pembersihan noise, model mencoba memprediksi video akhir yang bersih. Di sinilah CLA berperan. Alih-alih membiarkan model relighting melihat setiap frame secara terpisah, CLA memaksa model untuk memperhatikan informasi dari seluruh frame secara bersamaan. Caranya adalah dengan merata-ratakan fitur visual dari semua frame. Hasilnya, sumber cahaya yang dihasilkan menjadi jauh lebih stabil dan tidak bergeser secara acak diantara frame.
Modul ini meningkatkan interaksi antar frame dalam layer perhatian-diri (self-attention) untuk menstabilkan sumber cahaya latar belakang.
CLA menggunakan strategi dual-stream attention fusion:
- Stream asli: memproses setiap frame secara independen.
- Stream rata-rata: merata-ratakan fitur di seluruh dimensi temporal untuk mengurangi fluktuasi frekuensi tinggi.
- Hasil akhir adalah gabungan tertimbang dari kedua stream, menciptakan sumber cahaya yang stabil.
Progressive Light Fusion (PLF)
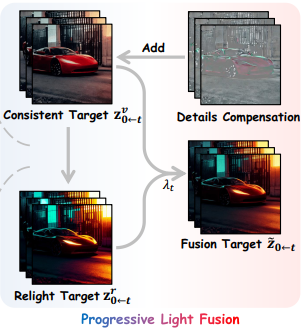
Setelah mendapatkan versi video dengan pencahayaan baru yang stabil dari modul CLA, langkah selanjutnya adalah menggabungkannya ke dalam video asli. Namun, penggabungan ini tidak dilakukan secara tiba-tiba. PLF melakukannya secara bertahap. Pada awal proses pembersihan noise, efek pencahayaan baru ditambahkan. Seiring berjalannya waktu dan video menjadi semakin jelas, efek pencahayaan baru perlahan-lahan dikurangi. Ini memastikan transisi yang mulus dan mencegah munculnya artefak visual yang aneh.
Metode ini mengadopsi prinsip fisika independensi transport cahaya, strategi ini secara progresif menerapkan linear blending antara tampilan video asli dan tampilan yang telah melalui proses relighting. PLF bekerja selama proses denoising dalam model difusi video:
- Hasil relighting dari modul CLA digunakan sebagai target relighting.
- Bobot menurun seiring berjalannya proses denoising, secara bertahap mengurangi pengaruh target relighting.
- Metode ini memastikan transisi pencahayaan yang mulus antar frame.
Data
Light-A-Video tidak memerlukan dataset khusus untuk training karena memanfaatkan model relighting untuk gambar dan model difusi video yang sudah ada sebelumnya:
Namun, untuk melakukan evaluasi dan perbandingan, para peneliti membuat sebuah dataset pengujian sendiri yang terdiri dari 73 video. Video-video ini diambil dari sumber-sumber publik:
- Dataset DAVIS: Terkenal karena berisi video dengan objek yang bergerak secara signifikan dan kaya makna.
- Pixabay: Sebuah platform yang menyediakan video berkualitas tinggi dengan beragam gerakan.
Implementasi
Dalam praktiknya, implementasi Light-A-Video dijelaskan sebagai berikut:
- Secara default, mereka menggunakan IC-Light untuk relighting gambar dan AnimateDiff (v3) sebagai model video diffusion.
- Video sumber diberi noise sebesar 50%. Kemudian, proses denoising (penghilangan noise) dilakukan dalam 25 langkah.
- Pada modul CLA, parameter gamma diatur ke 0.5, yang berarti ada keseimbangan antara memperhatikan fitur frame individual dan fitur rata-rata dari seluruh video.
- Pada modul PLF, bobot fusi lambda diatur agar menurun secara linear seiring langkah denoising, memastikan efek pencahayaan diterapkan secara progresif.
- Semua eksperimen dijalankan pada satu GPU NVIDIA A100, dengan konsumsi memori sekitar 23GB untuk menghasilkan video 16 frame.
Kesimpulan

Light-A-Video berhasil mengatasi masalah yang muncul dalam relighting video frame-by-frame, terutama dalam menangani inkonsistensi sumber cahaya dan tampilan relighted. Hasil eksperimen menunjukan:
- Peningkatan signifikan dalam konsistensi dari video relighted dibandingkan metode baseline (IC-Light, SDEdit, dan AnyV2V).
- Mempertahankan kualitas gambar yang tinggi sambil memastikan transisi pencahayaan yang koheren antar frame.
- Mendukung relighting langsung dari video sumber dan relighting foreground.
Sebagai metode training-free, Light-A-Video menawarkan solusi praktis untuk relighting video tanpa perlu mengeluarkan biaya untuk training yang besar atau kebutuhan dataset relighting video yang besar dan beragam. Meskipun masih memiliki keterbatasan dalam menangani perubahan pencahayaan yang dinamis, metode ini menyediakan dasar yang kuat untuk pengembangan teknik relighting video di masa depan.
Sumber
- Zhou, Y., Bu, J., Ling, P., Zhang, P., Wu, T., Huang, Q., … & Niu, L. (2025). Light-a-video: Training-free video relighting via progressive light fusion. arXiv preprint arXiv:2502.08590.
- Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. Advances in neural information processing systems, 33, 6840-6851.
- Zhang, L., Rao, A., & Agrawala, M. (2025). Scaling in-the-wild training for diffusion-based illumination harmonization and editing by imposing consistent light transport. In The Thirteenth International Conference on Learning Representations.
- Guo, Y., Yang, C., Rao, A., Liang, Z., Wang, Y., Qiao, Y., … & Dai, B. (2023). Animatediff: Animate your personalized text-to-image diffusion models without specific tuning. arXiv preprint arXiv:2307.04725.


