

Bayangkan Anda ingin membuat sebuah video pendek. Anda memerlukan aktor, kamera, lokasi, mikrofon, dan seorang sutradara untuk menyatukan semuanya. Proses ini rumit, mahal, dan memakan waktu. Kini, bayangkan jika Anda bisa menjadi sutradara hanya dengan mengetik sebuah skrip, memberikan foto aktor, dan menambahkan rekaman suara. Kecerdasan buatan (AI) kemudian akan menghasilkan video persis seperti yang Anda inginkan.
Inilah mimpi yang coba diwujudkan oleh teknologi Human-Centric Video Generation (HCVG). Namun, ada satu tantangan besar: AI sering kali kesulitan untuk menyeimbangkan tiga jenis perintah yang berbeda: teks, gambar, dan suara secara bersamaan. Terkadang, AI berhasil meniru wajah aktor dari foto tetapi mengabaikan instruksi dari teks.

Untuk mengatasi masalah ini, para peneliti dari Tsinghua University dan ByteDance memperkenalkan HuMo, sebuah kerangka kerja AI yang dirancang untuk menjadi “sutradara” yang cerdas, mampu berkolaborasi dengan ketiga jenis input tersebut.
Arsitektur
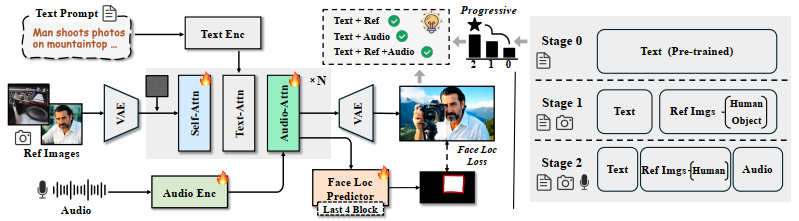
Struktur HuMo dirancang untuk mengintegrasikan tiga jenis data yang berbeda ke dalam satu proses generasi video.
- Pondasi (Model Dasar Text-to-Video): HuMo menggunakan model AI yang sudah ada, yaitu model Diffusion Transformer (DiT) berbasis Text-to-Video (T2V), sebagai arsitektur dasarnya. Pondasi ini sudah memiliki kemampuan yang kuat untuk mensintesis video dari deskripsi teks.
- Injeksi Gambar (Minimal-Invasive Image Injection): Untuk memasukkan informasi dari gambar referensi (misalnya, wajah seseorang), model ini mengambil representasi laten dari gambar tersebut dan menggabungkannya dengan data video yang sedang dalam proses generasi. Proses ini dirancang agar “minimal-invasif”, artinya tidak ada perubahan struktural besar pada arsitektur DiT asli. Pembaruan parameter selama pelatihan juga dibatasi hanya pada lapisan-lapisan tertentu (self-attention) untuk memastikan kemampuan asli model dalam memahami teks dan menghasilkan visual tidak terganggu.
- Sinkronisasi Audio dengan “Fokus Terpandu” (Focus-by-Predicting): Input audio diintegrasikan ke dalam setiap blok DiT melalui lapisan audio cross-attention. Untuk meningkatkan sinkronisasi antara suara dan gerakan bibir, HuMo tidak memaksa model untuk fokus pada area mulut. Sebaliknya, ia menggunakan strategi “fokus terpandu”. Sebuah prediktor masker dilatih secara terpisah untuk memperkirakan lokasi wajah di dalam video. Prediksi ini kemudian digunakan sebagai regularisasi lunak yang secara implisit membimbing model untuk memberikan perhatian lebih pada area wajah saat memproses data audio, tanpa membatasi kemampuannya untuk memodelkan gerakan seluruh tubuh.
Data
Kelangkaan dataset yang berisi video dengan pasangan teks, gambar referensi, dan audio yang selaras menjadi hambatan dalam melatih model semacam ini. Untuk mengatasinya, para peneliti membangun pipeline pemrosesan data untuk membuat dataset mereka sendiri.
Prosesnya terdiri dari beberapa tahap:
- Tahap 0 (Teks): Dimulai dengan kumpulan video berskala besar, deskripsi teks yang mendetail dihasilkan untuk setiap video menggunakan model VLM.
- Tahap 1 (Gambar): Untuk setiap subjek dalam video, sistem akan mencari gambar referensi yang cocok dari gambar berskala miliaran. Gambar yang dicari memiliki identitas yang sama tetapi dengan atribut visual yang berbeda (misalnya, pose atau pakaian yang berbeda) untuk mendorong model mempelajari identitas subjek alih-alih sekadar meniru gambar.
- Tahap 2 (Audio): Kumpulan data dari tahap sebelumnya disaring lebih lanjut untuk memilih video yang memiliki trek audio yang sinkron dengan gerakan bibir, menggunakan teknik analisis keselarasan bibir-suara.
Pipeline ini menghasilkan dataset multimodal berkualitas tinggi yang terdiri dari jutaan sampel video-teks-gambar dan puluhan ribu sampel yang juga menyertakan audio.
Proses Pelatihan
HuMo dilatih menggunakan paradigma progresif yang terdiri dari dua tahap untuk memastikan setiap kemampuan dipelajari secara efektif tanpa mengganggu kemampuan lainnya.
- Tahap 1: Pelatihan Preservasi Subjek. Pada tahap pertama, model hanya dilatih untuk tugas menjaga konsistensi subjek menggunakan input teks dan gambar. Modul yang berhubungan dengan audio dinonaktifkan sepenuhnya. Pembaruan parameter hanya dilakukan pada lapisan self-attention untuk menjaga stabilitas model yang sudah dilatih sebelumnya.
- Tahap 2: Pelatihan Sinkronisasi Audio-Visual. Setelah tahap pertama selesai, modul audio diaktifkan dan model mulai dilatih untuk tugas sinkronisasi audio-visual. Pelatihan ini menggunakan kurikulum progresif: pada awalnya, 80% dari proses pelatihan masih fokus pada tugas preservasi subjek, dan secara bertahap porsi tugas sinkronisasi audio ditingkatkan hingga 50%. Strategi ini memungkinkan transisi yang mulus dari input bi-modal (teks, gambar) ke tri-modal (teks, gambar, audio) dan memastikan kolaborasi antar modalitas dapat tercapai.
Implementasi
Apakah HuMo berhasil? Jawabannya adalah ya, dengan sangat mengesankan.
Ketika diuji dan dibandingkan dengan model-model canggih lainnya, HuMo menunjukkan keunggulan di berbagai aspek:
- Kepatuhan pada Teks: HuMo jauh lebih baik dalam menghasilkan detail-detail spesifik yang diminta dalam teks. Misalnya, jika teks meminta “pria bermain gitar perak”, HuMo akan menghasilkan gitar perak, sementara model lain mungkin mengabaikannya.
- Konsistensi Subjek: Identitas dan penampilan subjek dari gambar referensi dipertahankan dengan sangat baik, bahkan ketika ada banyak orang dalam satu adegan.
- Kualitas Visual: Video yang dihasilkan memiliki kualitas estetika yang lebih tinggi dan artefak (keganjilan visual) yang lebih sedikit, terutama pada bagian tubuh seperti tangan.
- Sinkronisasi Bibir: Gerakan bibir karakter sangat sinkron dengan audio yang diberikan, membuatnya terlihat alami saat berbicara.

Salah satu inovasi kunci saat implementasi adalah Time-Adaptive CFG, sebuah strategi yang secara dinamis menyesuaikan “fokus” model. Pada awal proses pembuatan video, model lebih mementingkan instruksi teks untuk membangun struktur adegan. Menjelang akhir, fokusnya beralih untuk menyempurnakan detail dari gambar dan audio. Ini seperti sutradara yang pertama-tama mengatur tata letak adegan, baru kemudian mengarahkan ekspresi detail dari aktornya.
Kesimpulan
HuMo mengatasi masalah utama dalam pembuatan video oleh AI, yaitu kesulitan menyeimbangkan perintah dari teks, gambar, dan audio. Dengan metodologi pelatihan progresif, arsitektur yang cerdas, dan dataset yang dibangun khusus, HuMo berhasil menciptakan video manusia yang tidak hanya berkualitas tinggi tetapi juga sangat dapat dikontrol.
Potensi teknologi ini sangat besar, mulai dari mendemokratisasi produksi film pendek hingga memungkinkan pembuatan konten yang lebih personal dan efisien. Namun, para peneliti juga menyadari adanya batasan dan potensi penyalahgunaan, seperti pembuatan deepfake. Langkah selanjutnya adalah terus meningkatkan skalabilitas dan kontrol model sambil mengembangkan pedoman etis yang ketat untuk penggunaannya.
Sumber:
- Chen, L., Ma, T., Liu, J., Li, B., Chen, Z., Liu, L., … & Wu, Z. (2025). HuMo: Human-Centric Video Generation via Collaborative Multi-Modal Conditioning. arXiv preprint arXiv:2509.08519.
- Hu, T., Yu, Z., Zhou, Z., Liang, S., Zhou, Y., Lin, Q., & Lu, Q. (2025). Hunyuancustom: A multimodal-driven architecture for customized video generation. arXiv preprint arXiv:2505.04512.
- Liu, L., Ma, T., Li, B., Chen, Z., Liu, J., Li, G., … & Wu, X. (2025). Phantom: Subject-consistent video generation via cross-modal alignment. arXiv preprint arXiv:2502.11079.
- Lin, G., Jiang, J., Yang, J., Zheng, Z., & Liang, C. (2025). Omnihuman-1: Rethinking the scaling-up of one-stage conditioned human animation models. arXiv preprint arXiv:2502.01061.


